Use bucketing for fairness grouping features
Follow the instructions below to learn how to perform a fairness evaluation and use bucketing to define custom groups within a fairness grouping feature.
Prerequisites
- You have accepted the license agreement and downloaded the Toolkit .zip file to your local system.
- You have installed the reference models package to your local system.
Alert: Windows 10 Users
Before you run a scan, you must disable QuickEdit Mode in your terminal window. Right click in the terminal window and uncheck the QuickEdit Mode option.
If you do not disable this option, clicking off your terminal window and back into your terminal window will cause the window to freeze and you will not receive your scan results updates.
Tutorial Instructions
To learn more about how Certifai calculates fairness refer to here.
Set your working directory to the folder where your Certifai Toolkit was unzipped.
cd <toolkit-location>Activate the virtual environment you created for
certifaiwhen installing the Certifai CLI.conda activate certifaiCopy and save the following starter scan definition into a text file named
fairness_bucketing_tutorial_scan_definition.yamlin theexamples/definitionsdirectory.scan:output:path: ../fairness_bucketing_tutorial_reportsmodel_use_case:author: info@cognitivescale.comdescription: 'In this use case, each entry in the dataset represents an auto insuranceclaim. The learning task is to predict the final settled claim amount.This dataset was originally sourced from Emcien: https://www.sixtusdakurah.com/resources/The_Application_of_Regularization_in_Modelling_Insurance_Claims.pdf'model_use_case_id: c12e/datasciencelab/auto_insurancename: 'Insurance: Auto Insurance Claims'task_type: regressionevaluation:description: Example evaluation against a single model.evaluation_dataset_id: evalevaluation_types:- robustnessname: Example Auto Insurance evaluationprediction_description: Amount of Settled Claimprediction_favorability: orderedfavorable_outcome_value: increasedregression_standard_deviation: 0.5models:- model_id: linl1description: Scikit-learn linear regression using Lasso with L1 regularizationname: L1 Linear Regressionpredict_endpoint: http://127.0.0.1:5111/auto_insurance_linl1/predictdatasets:- dataset_id: evaldescription: 1000 row representative sample of the full datasetfile_type: csvhas_header: truename: Evaluation dataseturl: file:../datasets/auto_insurance_eval.csvdataset_schema:outcome_column: Total Claim AmountThe above scan definition is a simplified version of the
auto_insurance_scanner_definition.yamlfile provided in the toolkit. This definition contains minimal information to only perform a robustness evaluation on a single model (made available by the reference model server).Note: The dataset path in the above YAML is relative to the location of the scan definition. The path is assuming your YAML file is located at
<toolkit-location>/examples/definitions. You may have to adjust the dataset path if you saved your scan definition in a different location.Add
fairness_grouping_featuresnames to the example scan definition to perform a fairness evaluation.Fairness grouping features are specified at the
evaluationlevel of a scan definition, under thefairness_grouping_featuresfield. Each grouping feature must specify anamethat must correspond to a column in the evaluation dataset. Additionally, each grouping feature provides abucketsfield where you can define custom groups within that feature. The syntax for defining a bucket depends on whether the grouping feature is numerical or categorical.Info
You can refer to the glossary under Data Types if you are unfamiliar with the difference between numerical and categorical features.
The scan definition in this tutorial analyzes the
IncomeandEmploymentStatusfeatures in its evaluation. Update theevaluationsection of the scan definition by adding "fairness" as anevaluation_type, and listingIncomeandEmploymentStatusunderfairness_grouping_features.Note: Fairness grouping features are case-sensitive and must match the column names in the specified dataset.
The
evaluationsection should look like the following before proceeding to the next step:evaluation:description: Example evaluation against a single model.evaluation_dataset_id: evalevaluation_types:- robustness- fairnessname: Example Auto Insurance evaluationprediction_description: Amount of Settled Claimprediction_favorability: orderedfavorable_outcome_value: increasedregression_standard_deviation: 0.5fairness_grouping_features:- name: Income- name: EmploymentStatusDefine
bucketsfor the numeric feature:Income.Info
Bucketing can be used to define groups within a single fairness grouping feature. This can be useful when attempting to view fairness across a combination of classes within the grouping feature, or when individual classes contain an insufficient number of samples to accurately be compared with larger classes.
By default Certifai will treat each distinct value as a separate class within a grouping feature. With regards to
Income, this default behavior would result in many classes containing only a handful samples. For example, only one person in the evaluation dataset has an income of$50,333. Furthermore, performing a fairness evaluation on a feature with classes with such minimal sample size would likely result in an unreliable fairness score.Using bucketing to define classes based on income ranges provides larger sample sizes. The result of this evaluation illuminates any bias the model has towards individuals in lower or higher income ranges.
Below is a table with the three classes to define for the
Incomefeature and the number of samples in each class.Income Range Number of instances $0 - $25,000 376 $25,000 - $60,000 320 $60,000+ 304 Buckets for numerical features are based on upper bound limits that can specify an optional
maxfield. Values belong to the bucket with the lowest upper bound greater than or equal to the value, and exactly one bucket must omit an upper bound to act as a "catch-all" bucket. Additionally, each bucket must have adescriptionfield that is used as the group name in the fairness report.The YAML equivalent for the classes defined above is shown below. Replace the
Incomeitem in thefairness_grouping_featureslist of your scan definition with the YAML snippet below.name: Incomebuckets:- description: "$0 - $25,000"max: 25000- description: "$25,000 - $60,000"max: 60000- description: "$60,000+"Note: The maximum is inclusive. For example, an income of exactly
25000would belong to the class"$0 - $25,000".Note: The class
"$60,000+"does not specify a maximum value and therefore includes all samples with an income of $60,000 or greater.The
fairness_grouping_featuressection should look like the following before proceeding to the next step:fairness_grouping_features:- name: Incomebuckets:- description: "$0 - $25,000"max: 25000- description: "$25,000 - $60,000"max: 60000- description: "$60,000+"- name: EmploymentStatusDefine
bucketsfor the categorical featureEmploymentStatus. Below is the distribution of values for theEmploymentStatusfeature in the evaluation dataset:Group Number of instances Employed 635 Unemployed 233 Retired 36 Disabled 44 Medical Leave 52 The goal of this evaluation is to illuminate the models' bias towards individuals who are actively working, versus those who are not actively working, regardless of unemployment category (unemployed, retired, disabled, or on medical leave).
Define the following buckets for the
EmploymentStatusgrouping feature:Actively Working- Includes:EmployedNot Actively Working- Includes:Unemployed,Retired,Disabled, andMedical Leave
Info
One reason to use bucketing in this case is that there are many fewer instances of the
Unemployed,Retired,DisabledandMedical Leaveclasses in the evaluation dataset compared to theEmployedclass. Another reason is to avoid theRetired,Disabled, andMedical Leaveclasses from having insufficient samples to compute an accurate burden.Buckets for categorical features are defined by lists of labels comprising the bucket. Each bucket must specify a
valuesfield with the list of labels in the bucket and adescriptionfield that will be used as the group name in the fairness report.The YAML equivalent for the classes defined above is shown below. Replace the
EmploymentStatusitem in thefairness_grouping_featureslist of your scan definition with the YAML snippet below.name: EmploymentStatusbuckets:- description: "Actively Working"values:- Employed- description: "Not Actively Working"values:- Unemployed- Retired- Disabled- Medical LeaveThe
fairness_grouping_featuresfield should look like the following before proceeding to the next step:fairness_grouping_features:- name: Incomebuckets:- description: "$0 - $25,000"max: 25000- description: "$25,000 - $60,000"max: 60000- description: "$60,000+"- name: EmploymentStatusbuckets:- description: "Actively Working"values:- Employed- description: "Not Actively Working"values:- Unemployed- Retired- Disabled- Medical LeaveOpen a new terminal and activate the virtual environment where you installed the reference model server.
conda activate certifai-reference-modelsStart the reference model server.
startCertifaiModelServer(Optional) Validate and test your scan definition before running the scan. Make sure to switch to the original terminal you were using for this tutorial and save the scan definition you have been working on.
Validate that the scan definition is syntactically correct. If you encounter any errors, verify that you have correctly followed the steps above and updated your scan definition. If the validation is successful, continue to testing your definition.
certifai definition-validate -f examples/definitions/fairness_bucketing_tutorial_scan_definition.yamlTest that the scan definition correctly connects to the model hosted by the reference model server. If you encounter any errors, verify that the reference model server is running and the model definition matches the result of the previous steps. If the test is successful continue to the next step.
certifai definition-test -f examples/definitions/fairness_bucketing_tutorial_scan_definition.yamlRun the scan:
certifai scan -f examples/definitions/fairness_bucketing_tutorial_scan_definition.yamlNote: The scan may take a few minutes to finish.
After the scan completes, you should see output similar to the following:
...Scan Completed====== Report Summary ======Total number of evaluations performed: 3Number of successful reports: 3Number of failed reports: 0Start the Certifai Console and navigate to the fairness results for this scan.
certifai console examples/fairness_bucketing_tutorial_reportsThe Console is available at:
http://localhost:8000. Click the URL or copy it into a browser to view your scan result visualizations.The Console opens on the Use Case list page. Click the menu icon on the far right of the row with the model use case id
c12e_datasciencelab_auto_insurance. Then click theScan Listbutton to view the list of scans for the model use case.
From the Scan List page, find the row with the Scan ID of the scan you ran in step 9. Then click the menu icon on the far right of the row and click the
Resultsbutton.
At the top right of the page, you can toggle between the Model and Evaluation views. View by Model is the default.
Last, scroll down to the
Fairness Breakdown by Grouping Featuresection of the results page.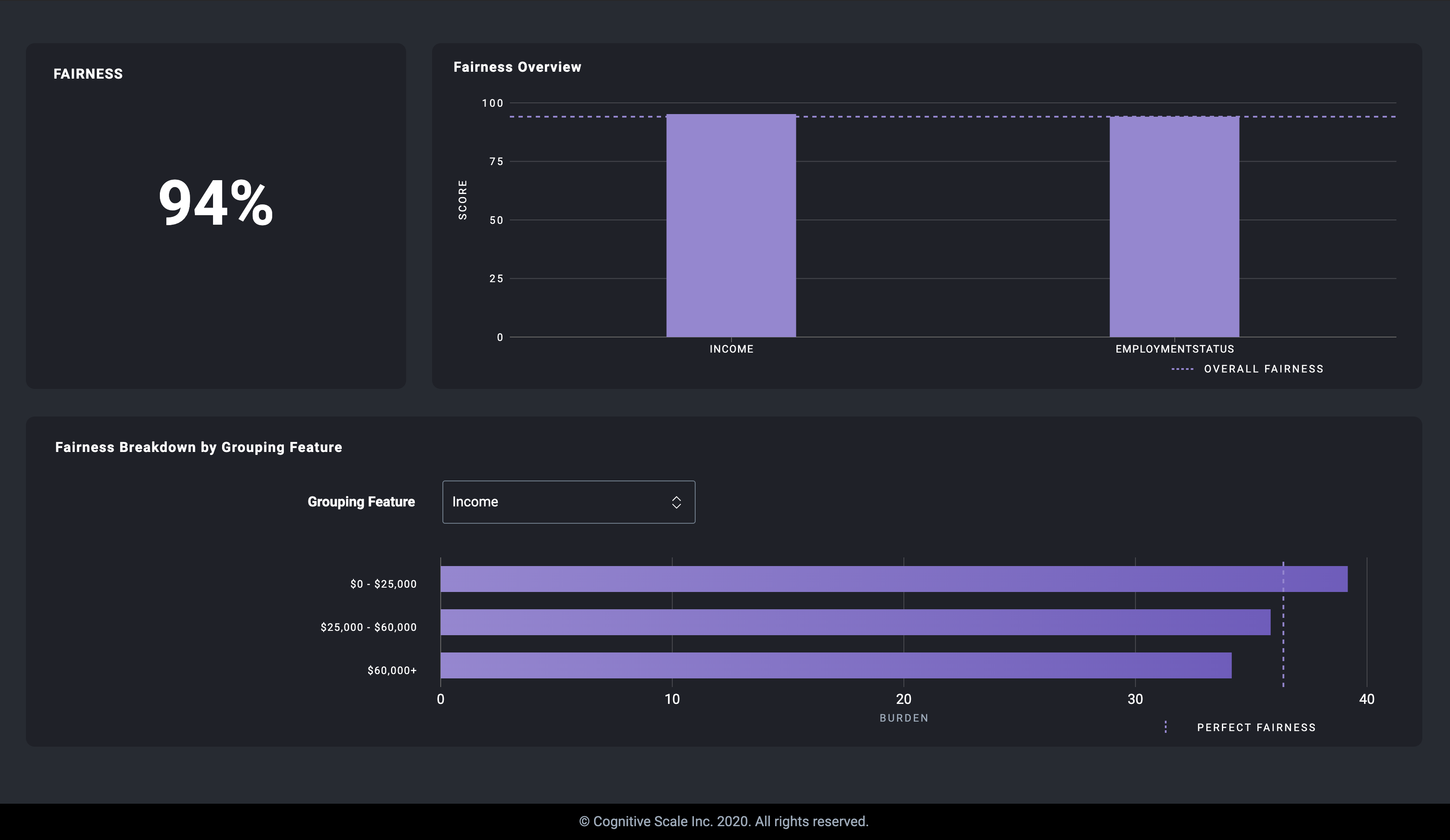
For more information on navigating the console refer to here.
Interpret the fairness results per grouping feature in the console.
Note: The results in your Console view may differ slightly from the images provided. The explanations below correspond to the results of the scan at the time of writing this tutorial.
Select
Incomefrom the "Grouping Feature" dropdown menu to view the group burdens for theIncomefeature. The fairness breakdown graph displays the burden for each group we defined in step 5.According to the results, the groups with an income ranges of
"$0 - $25,000"and$25,000 - $60,000"have a slightly higher burden than the group of individuals that earn more than$60,000. A higher burden value in this context means that more change is generally required to receive an increased settled claim amount.The fairness score for the
Incomegroup is95.21out of 100 because the burden across the three groups is relatively close. This may be interpreted to mean that the model is generally fair across the three income groups.Select
EmploymentStatusfrom the Grouping Feature dropdown menu to view the group burdens for theEmploymentStatusfeature. The fairness breakdown graph displays the burden for each group defined in step 6.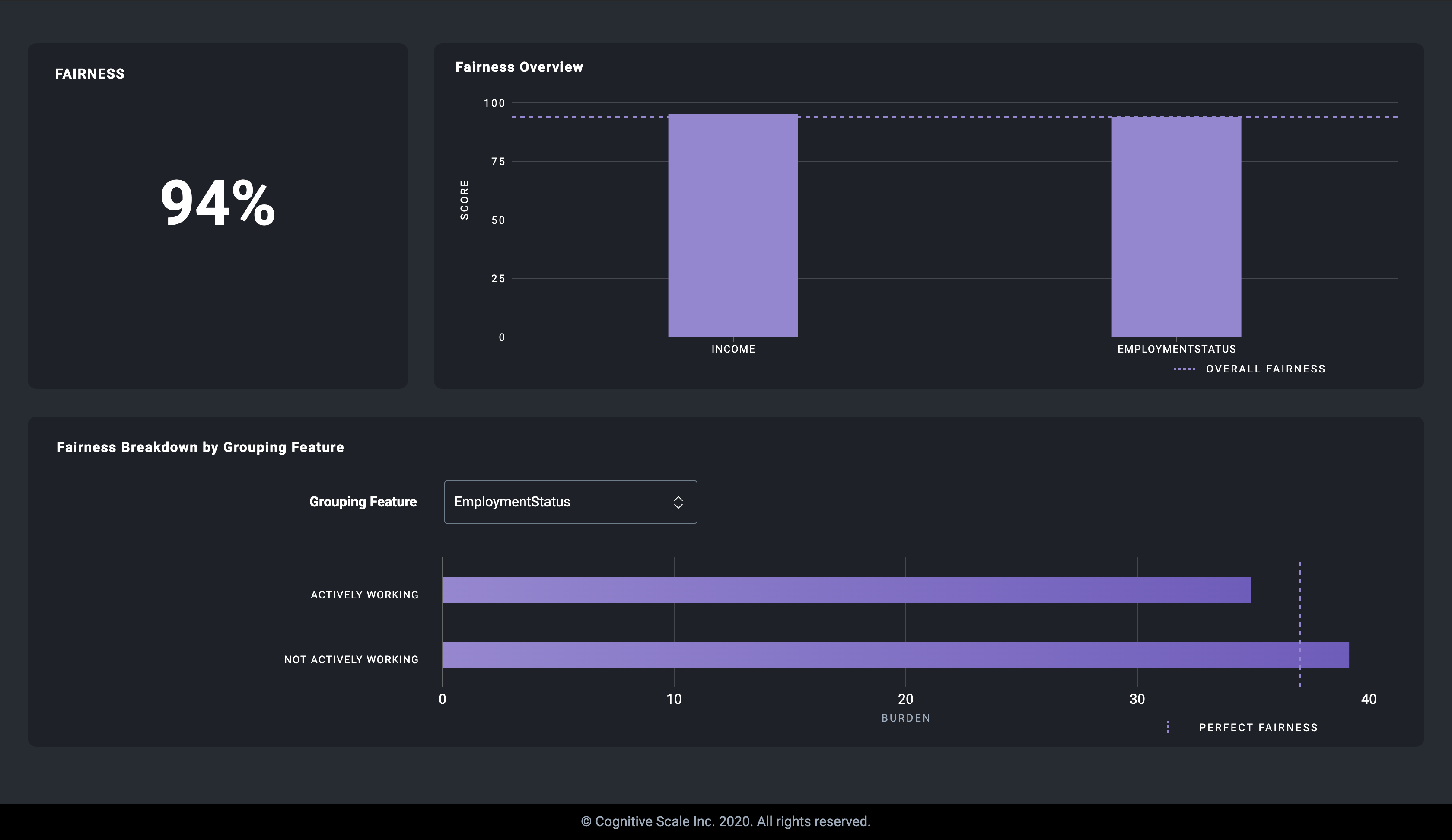
According to the results, the
"Not Actively Working"group has a higher burden than the"Actively Working"group. Again, a higher burden value in this context means that more change is generally required to receive an increased settled claim amount.The fairness score for the
EmploymentStatusgroup is94.08out of 100 because the burden across the two groups is relatively close. This may be interpreted to mean that the model is generally fair to both groups.