 Cortex Charts
Cortex ChartsKafka
Kafka is an events streaming platform built on a commit log that can be subscribed to and publish data. It is highly scalable and fault tolerant. In addition it provides the ability to manipulate data as it arrives. Kafka works with Kubernetes orchestration on any cloud provider platform.
Kafka Use Cases in Fabric
In Fabric Kafka:
- Adds buffering for Agent invokes to handle peak throughput.
- Assures that Agent invokes are delivered at least once, even following Gateway restarts.
- Allows for autoscaling
Currently Kafka is not used to:
- Manage Skill to Skill message throughput within an Agent
- Manage data streaming to Profiles
How Kafka works
Fabric's Processor Gateway now supports "worker" threads for Agent execution. By default 4 workers are deployed and each worker handles 4 parallel threads. This separates request handling from Agent execution.
Increased CPU usage which makes autoscaling more consistent. On the other hand, resource utilization is increased.
Fabric users will not interact with agents differently when Kafka is enabled, but several difference occur under the covers.
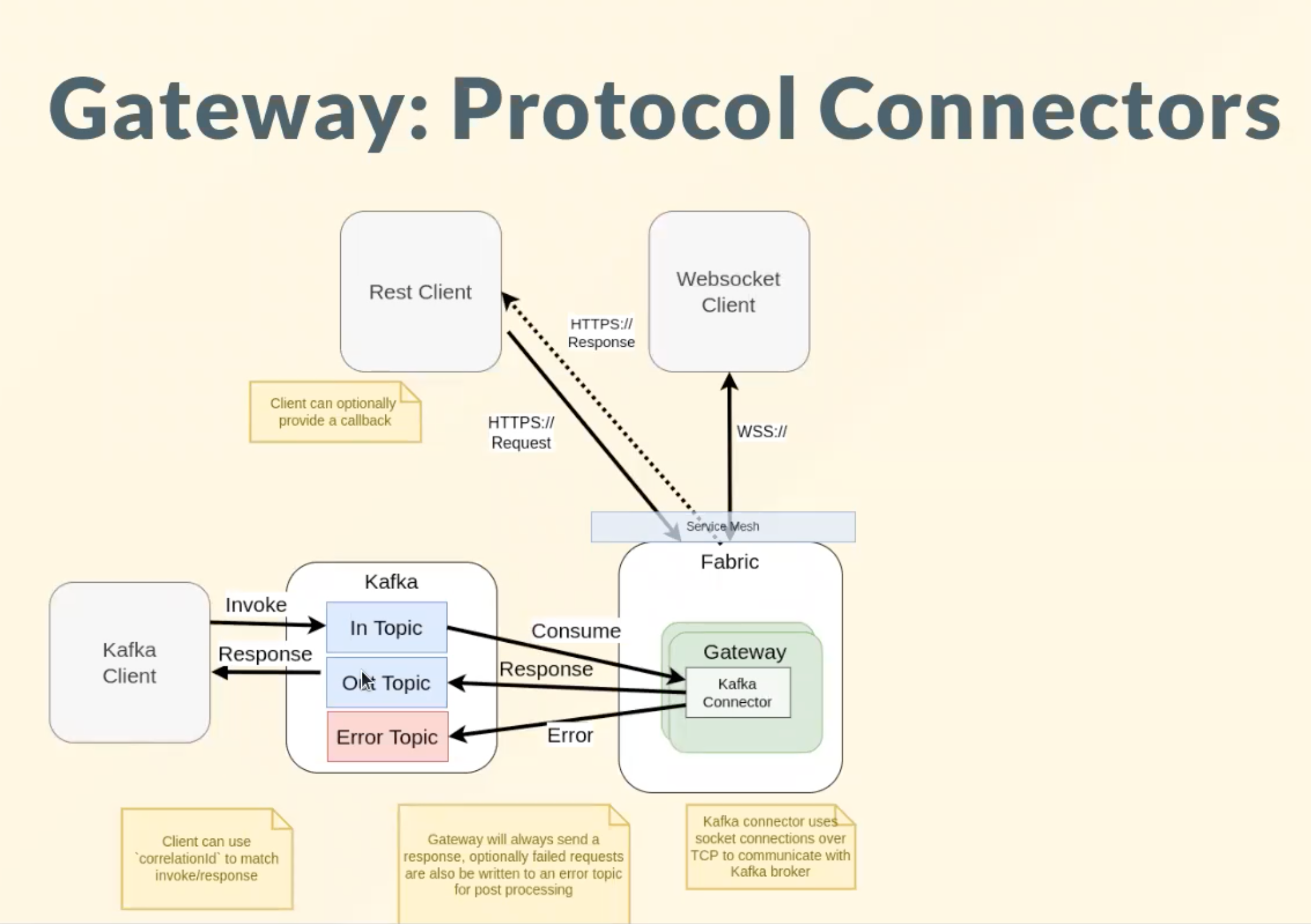
Invokes are written to
inTopicThe topic format is similar to Fabric's REST
agent invoke.Headers are supported for authN and propagation to Skills
EXAMPLE
{"agentName": "cortex/hello.agent","projectId": "myProject","serviceName": "inputService","correlationId": "ckyoj...","properties": {"..."},"sessionId": "","payload": {"numbers":[2, 14, 23]}}NOTE: agentName, projectId, and serviceName are required.
Responses are received from
outTopic. The Gateway always sends a response.EXAMPLE
{"activationId": "8e88d261-xxx","correlationId": "cxyvxxxx","response":{"sum": 39},"status": "COMPLETE"}(OPTIONAL) The errorTopic provides insight into errors and exceptions.
IMPORTANT
When creating topics in Kafka, the number of partitions in the topic must be greater than or equal to the max number of processor-gateway pods allowed to run within the cluster.
Kafka Setup
Kafka setup must be performed by a System Administrator or DevOps Engineer.
Two requirements must be met to setup Kafka in Kubernetes:
Workers must be enabled by setting
FEATURE_AGENT-WORKERS=true.NOTE: This feature may be enabled without using Kafka, but it is required to use Kafka.
A connector config map,
gateway-connector-configs, must be provided using podspec.EXAMPLE
{"name": "kafkaDefault","type": "kafka","kafka": {"config": {"clientId": "gateway","brokers": ["192.168.138:30942"]}}}
NOTE
When creating topics in Kafka, the number of partitions in the topic must be greater than or equal to the max number of processor-gateway pods allowed to run within the cluster.
Strimzi
Strimzi provides a way to run an Apache Kafka cluster on Kubernetes in various deployment configurations.
The Strimzi operator can be deployed as an extra Helm chart installation.
Add the Strimzi Helm Chart Repository:
helm repo add strimzi https://strimzi.io/charts/Install the Strimzi Operator into a kafka namespace:
helm upgrade --install strimzi strimzi/strimzi-kafka-operator -n kafka --version 0.26.1Create a Kafka instance and topics for Fabric via Strimzi's Custom Resource Definitions (the following example contains a Kafka instance named fabric-cluster and topics named fabric-in and fabric-out):
apiVersion: kafka.strimzi.io/v1beta2kind: Kafkametadata: name: fabric-clusterspec: kafka: replicas: 1 listeners: - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true authentication: type: tls - name: external port: 9094 type: nodeport tls: false storage: type: jbod volumes: - id: 0 type: persistent-claim size: 10Gi deleteClaim: false config: offsets.topic.replication.factor: 1 transaction.state.log.replication.factor: 1 transaction.state.log.min.isr: 1 zookeeper: replicas: 1 storage: type: persistent-claim size: 10Gi deleteClaim: false entityOperator: topicOperator: {} userOperator: {}---apiVersion: kafka.strimzi.io/v1beta2kind: KafkaTopicmetadata: name: fabric-in labels: strimzi.io/cluster: "fabric-cluster"spec: config: retention.ms: 3600000 partitions: 3 replicas: 1---apiVersion: kafka.strimzi.io/v1beta2kind: KafkaTopicmetadata: name: fabric-out labels: strimzi.io/cluster: "fabric-cluster"spec: config: retention.ms: 3600000 partitions: 3 replicas: 1Apply the above yaml file with kubectl to have the operator create the Kafka instance/topics:
kubectl apply -f kafka.yaml -n kafka